RPC学习
一个简单的rpc学习项目
感觉从零开始写一个rpc还是挺有意思的,准备用java和go都尝试实现一遍
全文皆为个人理解
rpc是什么?
rpc本质就是把真正处理业务的逻辑和其他框架解耦,在需要的时候请求server端,拿到具体接口的实现类
-
客户端发出网络请求(例如 TCP 或 HTTP)
-
服务端接收请求,找到对应的方法并执行
-
将结果序列化后返回
-
客户端反序列化,得到结果
最小实现
用java原生的socket编程就可以实现,但是会受到很多性能限制,比如socket传输是同步阻塞的,序列化读写性能差,注册和发现服务不方便等等,所以需要引入其他中间件来解决:
- Netty
- Protobuf, Triple等序列化协议
- ZK
Netty加入
Netty工作模式如下:
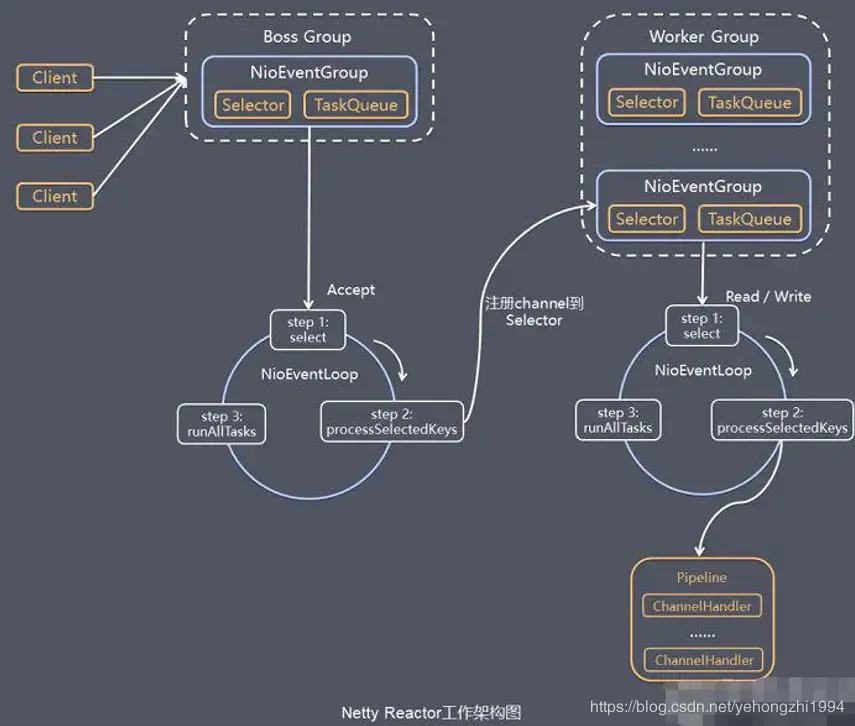
一些对用到的组件的理解⬇️
EventLoopGroup:循环事件群,本质是执行循环任务的线程池
EventLoop:循环事件线程,每个线程对应一个channel,执行这个channel内的任务(单线程对应是为了防止锁的竞争)
EventLoopGroup bossGroup = new NioEventLoopGroup(1); // 接收连接
EventLoopGroup workerGroup = new NioEventLoopGroup(); // 处理I/O事件
在server端的实现中,一个boss负责接收channel中传输的信息(RpcRequest),并且把链接中的任务发送给worker
Bootstrap:Netty提供的方便的服务搭建框架,类似于Stream的流式调用
public void start(int port) throws InterruptedException {
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
ChannelPipeline p = ch.pipeline();
// 编解码:Java对象 <-> ByteBuf
p.addLast(new RpcDecoder(RpcRequest.class));
p.addLast(new RpcEncoder(RpcResponse.class));
// 自定义逻辑
p.addLast(new RpcServerHandler(service));
}
})
.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.SO_KEEPALIVE, true);
ChannelFuture f = b.bind(port).sync();
f.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
Channel:对TCP链接的抽象封装
ChannelPipeline:根据ChannelHandler,流水线式的处理管道中的信息
Netty规定数据流向有两种,inbound和outbound
(入站方向) ↓ decode → validate → business → ... Socket → ───────────────────────────────────────→ 应用逻辑 ↑ encode ← compress ← response ← ... (出站方向)
多协议支持
在写多协议支持时,一开始很顺利,简单导入依赖就可以跑起来
一开始序列化协议读取非常简单:
switch (serializerName) {
case "java":
serializer = new JSerializer();
break;
case "json":
serializer = new JsonSerializer();
break;
case "kryo":
serializer = new KryoSerializer();
break;
default:
throw new RuntimeException("Unsupported serializer: " + serializerName);
}
但是后来想写的优雅一点,把配置都写进一个yaml里面,服务启动的时候再静态加载,写着写着感觉不大对,因为理论上来说服务器端启动后不管传过来的是什么协议,都应该能自动解析,于是问题复杂度骤增
问了下gpt,原来主流的rpc框架都是自己构造协议包的,在包头携带一些信息,用Netty中的解析器来读取
包头结构:
| 字段 | 如何构造 | 用途 |
|---|---|---|
| magic | 固定值 | 防止脏数据 |
| version | 固定 1 | 兼容版本 |
| serialization | 用户配置 | 解析 body |
| messageType | 请求/响应 | 知道 body 类型 |
| requestId | 自动生成 | 关联请求/响应 |
| bodyLength | body.length | 帮助解码 |
| body | 序列化后的 Request/Response | 真正业务数据 |
根据这个版本,设计RpcDTO包装我们的信息,并且对Encoder,Decoder,Client,Server都做出对应的修改,在这里受到了比较大的阻碍,因为对Netty的工作模式还是不大熟悉
梳理一下两边的业务逻辑:
-
RpcServer
- 根据配置读取端口,在端口启动服务
- 流水线中加入解码器和编码器
- 加入Handler,处理消息
- 根据DTO头选择协议,反序列化data为Request,构造Response
- 构造DTO,先填充包头信息,最后把序列化后的Response填入
-
RpcClient
-
读取配置
- 构造Request,调用sendRequest
- 根据配置和Request构造DTO,发送到Server端,阻塞等待响应
- 拿到响应的DTO后,根据包头的协议反序列化data为Response,返回Response.getResult()
- 根据result构建代理,返回proxy
-
初步来看应该存在一些线程安全问题和很多可以优化性能的点(比如线程复用),之后需要好好看看
ZooKeeper
Q:为什么需要ZK?
A:当前调用逻辑是写死的,Server端在固定的端口开启服务,Client端根据固定的地址请求服务,如此最多只能实现1:N的调用关系,非常不灵活。引入ZK可以把多个开启的服务作为一个集群,Client只需要访问集群地址,ZK提供负载均衡,分布式锁等服务
引入Zookeeper服务比较简单,重点在于需要调整原来的配置结构,首先更新一下RpcConfig,变得更优雅一点
application:
name: MyRpcClient
registry:
type: zookeeper
address: localhost:2181
timeout: 3000
server:
host: 127.0.0.1
port: 8090
client:
protocol: kryo
loadbalancer: random
这样子也方便了之后的功能扩展
目前的结构下其实服务端和客户端都是复用了本地的Zookeeper,如果以后要分离,应该再修改一下结构
再说说zk本身,ZooKeeper 是一个 分布式协调服务(distributed coordination service)。 它本质上是一个 强一致性、分布式的键值存储系统,可以和redis类比一下
| 功能 | Redis | ZooKeeper |
|---|---|---|
| 数据存储 | KV,可用于缓存/持久化 | KV,主要用于配置/元数据,偏向内存存储 |
| 监听机制 | Pub/Sub | Watcher,节点变化通知客户端 |
| 持久化 | 可选 RDB/AOF | 数据持久化到磁盘,但优化为读多写少 |
| 高可用 | 哨兵/Cluster | 内置 Leader/Follower 选举,保证一致性 |
| 端到端通信 | 不负责 | 不负责 |
负载均衡策略
添加了三种策略
- 随机选择:没什么好说的,就是每次都根据传输的列表大小随机选择一个节点,性能开销也小
- 轮询:用AtomicInteger作为索引index,每次使用都自增,然后取模得到应该选择哪个节点,原子类底层的并发安全依赖乐观锁CAS实现
- 一致性哈希:根据当前节点列表,把每个节点当成100个虚拟节点添加到哈希表中,每次取节点都根据线程id作为key尝试拿一个节点,如果拿不到就拿第一个节点
在压力测试中,发现随机选择的性能最好,一致性哈希写的有点问题,似乎每次请求都会重新哈希一次,导致性能差
实际应用中,一般不会每次请求服务都直接通过Zookeeper,而是和数据库一样,在本地做一个redis的内存缓存,优先从redis中拿链接,zk只在服务节点发生变化时通知